Lennonnet
(If you don’t want to read about books and personal struggles, skip to the TL;DR)
A few months ago, I read The Alignment Problem by Brian Christian. It’s a very good book about the problem of aligning “AI” behavior with human values. I don’t explain it as well as he does, but basically it’s about what can go wrong if you don’t define well what goals you want an AI to achieve.
I feel that too many people think that AI and machine-learning (ML) are some kind of magic where computers become alive. I think this is partly because even programmers of AI, especially in the case of Neural Networks (NN), don’t really know what’s going on inside the model that seems to be able to do some things better than us humans.
In a NN, what’s basically happening is that you take your input data, in the form of a vector, and you multiply it with with numbers (weigths), add some other numbers (biases) and send it through a non-linear function. You repeat this for a number of layers and when that’s a lot of layers, you call it a deep NN. The output of the NN is the response of the model to the input. For example, you send an image (vectors of RGB values) through the NN and the output is a label of what the image most probably is (cat, dog, bike, etc.). By sending a whole lot of pre-labeled data through the NN and tweaking the weights and biases each time, you can train the network to classify those images. It’s a little bit like fitting a curve through some data points. So in the end, you have a trained model, which can then do predictions. What’s making it seem magical, I think, is that generally, we can’t make much sense of what these weights and biases represent. But in the end it’s just simple mathematical functions.
So then I thought: if it’s so simple, then I should be able to do it!
And I found it very interesting to do some experiments with ML in pytorch while reading the book, and noticing the same problems as described in the book.
My goal was to make a very simple image classification model, based on Convolutional Neural Networks (CNN), which could tell me whether an image was John Lennon or not. Hence the name: Lennonnet.
I did a bit of reading online and it turns out you can just download CNNs and re-train them.
I combined this with some basic web-scraping to provide my training data.
After the first training, the results were less than satisfactory. My model just classified any person as 'john' and everything else as 'not_john'. The reason was probably that my training data contained a lot of pictures of John Lennon and a lot of pictures of random stuff, but not a lot of people that were not John Lennon.
So I suppose the NN just recognized if something was a person or not.
In a second step, I added a lot of pictures of people to the 'not_john' training set. That seemed to help.
Unfortunately, when I input a picture of Paul Mc Cartney into Lennonnet, it still classified it as 'john'.
Perhaps they look too much alike (especially in the first years of the Beatles, when they all had the same haircut).
So then I added a some pictures of the other Beatles in the 'not_john' dataset. I don’t know if this is cheating and I’m not sure that it helped.
TL;DR
I’m using pytorch in this project, combined with pytorch-lightning, because I had
learned about it in this course on pytorch by Full Stack Deep Learning,
which a friend recommended.
The alternative is tensorflow, which I’ve used in the past. I can’t really say which is better.
The steps I took to train and test the model are the following:
- Use web-scraping to download the training data: a bunch of John Lennon pictures and a bunch of pictures that are most likely not John Lennon
- Re-train an existing CNN
- Test the model on 100 John and 100 not-John images that weren’t used during training or validation
Getting the training data
As outlined in a previous post on web-scraping, I automatically downloaded
1320 images that I labeled as 'john'. I downloaded 11481 images that I labeled as 'not_john'.
Of course you can not just search for “not john lennon please” on Duckduckgo and hope you
won’t get pictures of John Lennon. Quite the opposite in fact! So I put some thought into
the composition of the 'not_john' dataset. I put 100 images of each of the other Beatles
in the set, hoping that this would teach the model the difference between John and the other
Beatles. Then I searched for “Person” a thousand times, hoping that this way the model
will not just classify any person (as opposed to non-persons) as John Lennon. Finally,
I used a website to generate 100 random words and I downloaded about 100 images for each word.
Re-training a ResNet-50d model
timm is a library that contains pre-trained computer-vision models, which you
can directly import in your python code. You can then re-use existing models, and re-train them if necessary.
I got a lot of inspiration from this
lengthy tutorial on how to use timm.
Ultimately, I trained the model for 32 ‘epochs’ - so basically passing all the training data
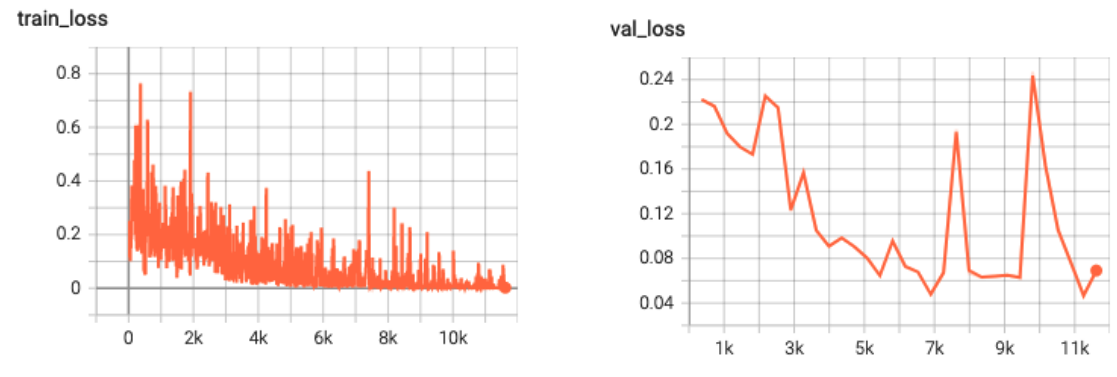
through the model 32 times, each time hopefully improving the performance. Using TensorBoard,
I could track the training and validation loss. Training loss reflects how well each image
is being categorized during training, and validation loss is the same but for the validation
data. Just after the training step, it evaluates how well the model does on data it hasn’t
seen yet. If all goes well, both curves should go down. If the training loss is really
low, but the validation loss is high, this typically means you’ve overfitted the model.
In this case it would mean that it can perfectly say that an image is John Lennon if it was
part of the training set, but not if it wasn’t. It’s like learning by heart
that 2x2 = 4 but not having a clue what 2x3 would be.
Putting all the code here would be too much, so I moved it to another page, in case you’re interested!
Testing the model
During training, we also validate the model each epoch, with in this case, 10% of the data.
However, the real proof is of course in the pudding. So before running the training, I removed
100 'john' and 100 'not_john' pictures and kept them for testing the model afterwards.
In my test, 96 of the 'john' and 99 of the 'not_john' pictures were classified correctly
by the model.
You can try out the model yourself in this Colab notebook:
![]()
It’s pre-loaded with an example of a John Lennon picture and a potato and of course it classifies both of them correctly:
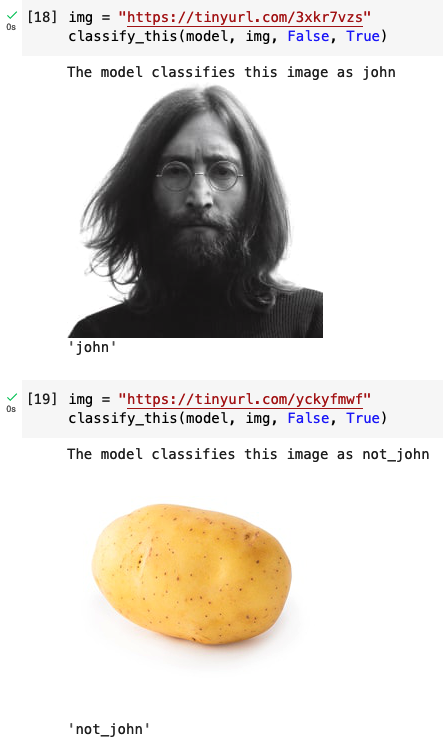
Unfortunately, George Harrison was also classified as John Lennon. I did not yet specifically test the performance of the model on other Beatles. It would be interesting to get some statistics on that too. Any ideas to improve this are welcome!
End notes
To be honest, I have no idea whether a 97.5% accuracy is good for an image classifier network. Frankly, I’m quite disappointed that it can’t see the difference between George Harrison and John Lennon. Then again, I didn’t do much tweaking of the model, nor do I know if I’m using the right model. And actually, ChatGPT isn’t always right either!
The training took several hours to run on my laptop. It was quite nice to have a hot laptop during winter. But again I have no clue if that is a reasonable time, or whether there’s a lot to be optimized.
Clearly, I’m not a machine-learning expert (yet!) but it was quite satisfying to get some results quite quickly. If anything, I learned a bit more about how neural networks work, and what are some of the problems and difficulties.
If you also want to learn about AI and ML an neural networks, don’t bother, computers will replace you soon enough!
2023-02-22 Update: Other Beatles predictions
Thanks Hans for pointing out that I should look closer at the probabilities generated by Lennonnet before judging its accuracy! Indeed, with that particular George picture, it predicted about 50% probability that it was John Lennon, so not exactly convincing. I was curious to see how accurate Lennonnet is on average for the non-John Beatles. So I downloaded 1000 pictures of each of the other three and fed them to the model. The result is pretty interesting. This picture shows the distribution of the predicted probability that a picture is John:
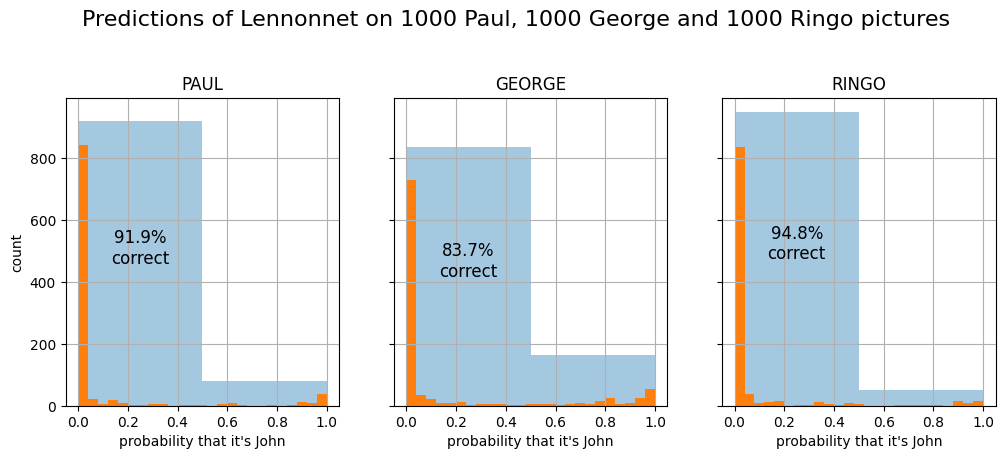
The orange bars show 25 bins, whereas the blue bars show 2 bins (right or wrong). Fortunately, most predictions are correct. What’s interesting is that George is predicted much less accurately than Paul and Ringo. Does this mean that George looks more like John than Paul and Ringo? I suppose it does.