Web scraping using Selenium in Python
Introduction
In a future post, I might explain how I succeeded in making an image classifier neural network (AI, Machine Learning, yay!). Or I might not, because I utterly failed. Or I might explain how I failed. I don’t know yet. The current state is that it will correctly identify a potato as not being John Lennon, but incorrectly identify George Harisson as being John Lennon. That corresponds more or less to my own level of distinguishing between Beatles when I was 8 years old.
But I digress.
I initially tried the same with pictures of my 1-year-old son Rinus. That seemed to work until it started labelling all babies as Rinus and later also my wife.
But I digress again.
The point is, you need training data to train the model. In the case of my son, that’s easy, because we literally have thousands of pictures of him. But obviously I couldn’t show off my ML skills with a Rinus-identifier because I hope not too many people on the internet have pictures of my 1-year-old son.
So I needed someone else to test my skills on. I didn’t feel like looking at thousands of pictures of Trump so in the end I decided on John Lennon.
And what better place to get thousands of training images from than www.google.com? www.duckduckgo.com of course!
Now, I didn’t want to go clicking a million times to download some pictures, so I did what every good engineer would do: find a way to do less work. Or very often: spend way too much time programming something that I could have done ten times manually in the mean time. In this case: web scraping!
As with all my programming endeavours, I googled (yup.) how to do it and this page kind of explains it. But it uses Chrome and Google and I didn’t want to install Chrome and I have great sympathy for duckduckgo so I used Firefox and duckduckgo (by the way, I’m all for google alternatives, but couldn’t they have come up with a name that is easier to type, like ducko or doogle or something?).
Anyways, it’s not all that hard to get this to work and I thought it might be interesting for others to try as well so I’ll tell you what I did.
Instructions
I recommend you try this in a virtual environment.
We’ll need to install Selenium to do the detection of stuff on websites, and wget to download things. You could probably find alternatives to download things in python so you don’t need to install wget - up to you!
In a terminal:
$ pip install selenium wget
In a python script or Jupyter notebook:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
from os import path, makedirs
import wget
import uuid
You know, imports. Then some script settings:
search_string = "john lennon" # Search string
download_folder = "Downloads/john" # Where to download images to
min_amount = 100 # Download at least this many images
The next bit of code will use the Selenium webdriver to launch Firefox (assumed to be installed), go to www.duckduckgo.com,
look for the searchbox, send the search_string to it and ‘click’ enter. Then wait a bit
for the page to load, find the ‘images’ button and ‘click’ it.
wd = webdriver.Firefox()
wd.get("https://www.duckduckgo.com")
search_box = wd.find_element(By.ID, "search_form_input_homepage")
search_box.send_keys(search_string + Keys.ENTER)
time.sleep(3)# wait to load
images_button = wd.find_element(By.CSS_SELECTOR, ".js-zci-link--images")
images_button.click()
Some explanation: The first 2 lines are self-explanatory. The third line uses a method of
the Selenium webdriver to find an element on the page. Some documentation here.
By specifying By.ID and a string, you tell it to go look for an element that has an id
attribute in its tag equal to that string. So how do you know what to look for?
Firefox has a nice feature where you can right-click on something on a web-page and choose Inspect.
When you do that, you should get a view as in the screenshot below:
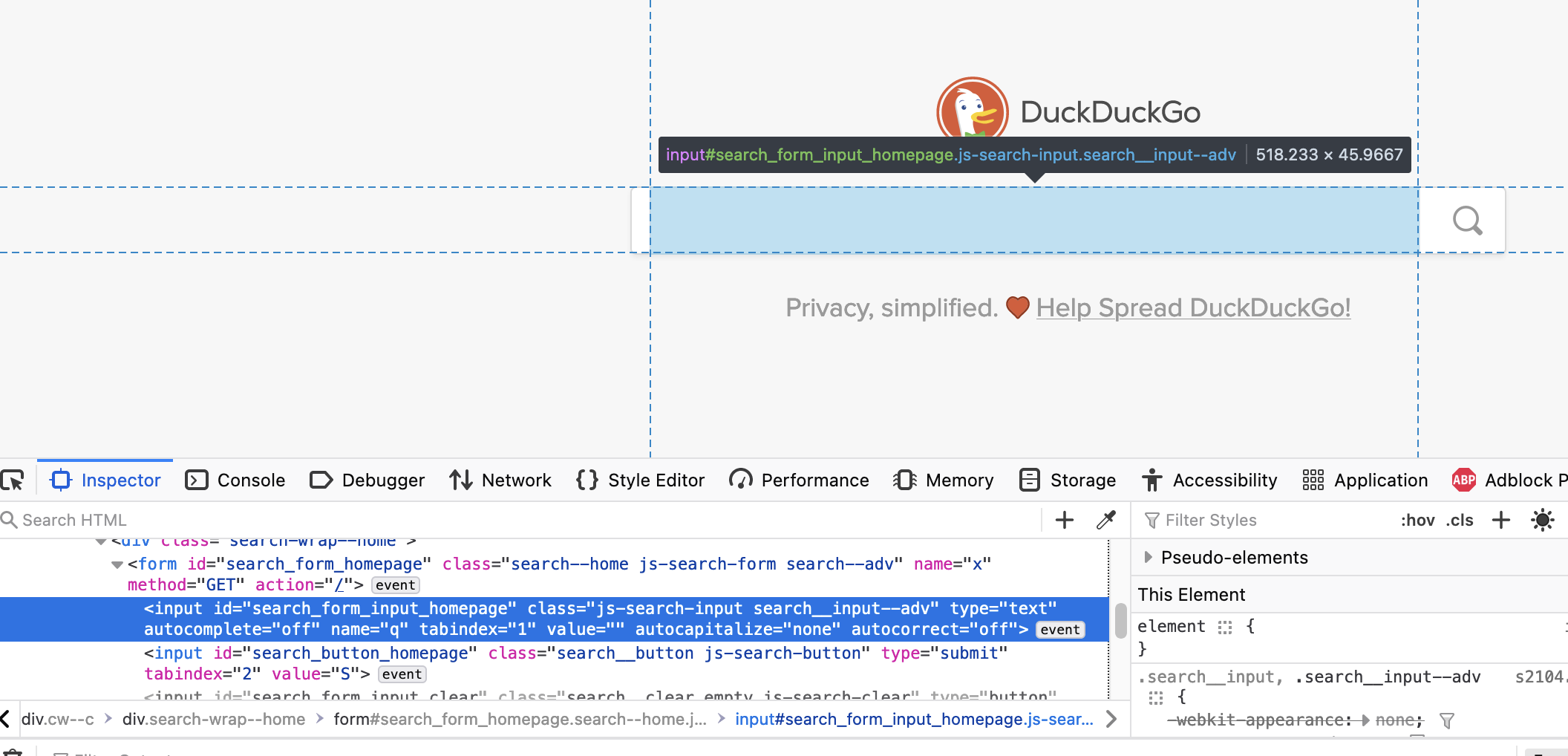
You can see the HTML-tag for an input element highlighted. The id="search_form_input_homepage" bit
is what we’re looking for here. That string is what we put in the find_element function.
On the next line of code, we use the element that we found and send some keys to it: The search_string
and an enter key. Just like you would do. You can actually watch it happening in the browser when you execute
the code.
Then we wait a bit for the page to load and find the images button. Again, we use the find_element
method but this time by CSS_SELECTOR. Just like a web-designer would look for elements
to style in CSS, as explained here.
By using the ‘.’-notation, we’re looking for a class.
If you would inspect the images button, you would see it has multiple classes in its tag. I suppose
I just chose the class that I thought would most likely only refer to this button. An id would
have been nicer, since that’s unique for each element, but this element didn’t have an id. So
I guess it’s a bit of trial and error.
Then after clicking the images button, the page with the results and thumbnails should load.
With the page loaded, we will do a loop where we collect the thumbnail elements using the
same find_element method as before, download the images and scroll down and repeat this until
we have more than enough images.
We define two functions to help us with that.
First, a function to download images, assuming we have obtained a list of elements on the page that represent the thumbnails (for training my neural network, I wasn’t interested in the high-resolution original images, the thumbnails would be sufficient).
def download_images(thumbnails, folder, filename_counter):
makedirs(folder, exist_ok=True) # create directory to save images
for pic in thumbnails:
url = "https:" + pic.get_attribute("data-src") # obtain thumbnail url
img_path = path.join(folder, f"img_{str(uuid.uuid1())[0:15]}.jpg")
wget.download(url, out=img_path) # use wget to download the image
filename_counter += 1
return filename_counter
Here, thumbnails is a list of Selenium WebElement objects. For each of them,
the url for the picture is in the data-src attribute of the html tag, see screenshot:
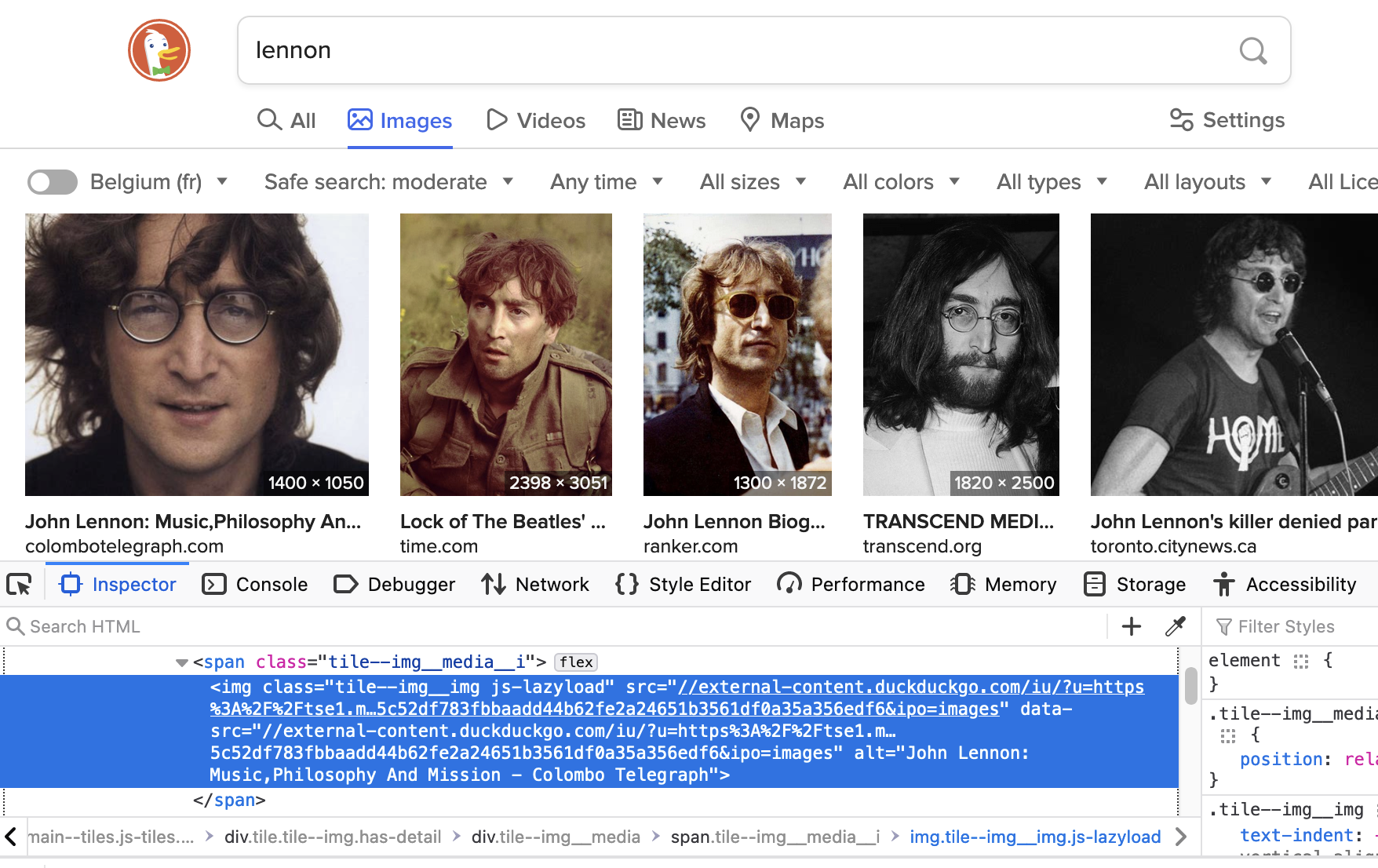
As you can see, it’s missing the http: part, so that’s prepended in the code. The img_path
variable is where we’ll store the image. I used the uuid module to generate random unique
names of 16 characters.
This scroll function, I copied from the article I mentioned in the beginning:
def scroll_to_end(wd):
"""Function to scroll down after saving all images in window"""
wd.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(1) # allow loading before continuing
Then the loop:
file_counter = 0
while file_counter < min_amount:
thumbnails = wd.find_elements(By.CLASS_NAME, "tile--img__img")
filename_counter = download_images(thumbnails,
folder=download_folder,
file_counter=file_counter)
scroll_to_end(wd)
And that’s it! Any smart programmer can see that it’s fairly easy to change the code to search for other images, like “cucumber” or “some cucumber” or “cucumbersome”.
Send me a message if you have questions or suggestions.
Good luck!
Notes
- Instead of searching for “John Lennon” on duckduckgo’s homepage and clicking the images
button, you can also just directly construct the url:
https://duckduckgo.com/?q=john+lennon&t=h_&iax=images&ia=imagesBut I thought it was interesting to show a couple of features of Selenium here. - I came across some pages that mentioned that I had to install a tool called geckodriver in order for Selenium to work with Firefox. In the end, I didn’t actually need it. But maybe depending on your Python/Selenium/Firefox version, you may need it.
- The page on towardsdatascience.com, specifically the second section on interactive pages, explains how to install ChromeDriver if you’re using Chrome.